Tekst Loïs Diallo
Foto Loïs Diallo (AI gegenereerd)
Of je alle 60.000 documenten op de netwerkschijf wilt indexeren en voorzien van metadata. Zodat ze van de schijf af en het archief in kunnen. Want de Provincie Gelderland wil het informatiebeheer, de basis, op orde maken. Met als hoger doel: betere sturing en transparantere besluiten en sneller informatie kunnen verstrekken aan inwoners. Omdat 60.000 best veel is, wilde data-architect Jeroen Cuppen van de provincie uitzoeken of AI hier uitkomst kan bieden. Een innovatief experiment in plaats van een klassieke ICT-oplossing.
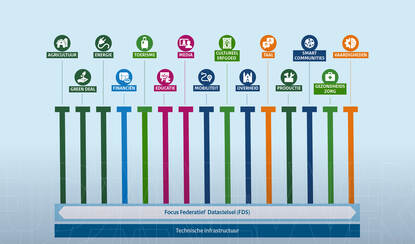
Cuppen, die binnen IPO werkt aan een interprovinciale data-architectuur en een federatief stelsel en gegevenswoordenboeken bouwt voor provincies, stelde een multidisciplinaire werkgroep samen. Een denktank. Met als belangrijkste doel: leren door te experimenteren: “We wilden zelf ontdekken wat er kan met de modernste Large Language Models (LLM).”
In de werkgroep dachten een datascientist, een inhoudelijk expert en kwaliteitscontroleur van de afdeling documentaire informatievoorziening (DIV, die het vraagstuk inbracht) en Lisa Holweg mee. Holweg is beleidsadviseur AI en digitale ethiek. “Een inspirerend team met verschillende bloedgroepen. Daarom werkte het erg goed.”
AI is een persoonlijke interesse van Cuppen: “Door LLM kunnen computers opeens iets wat ze eerder niet konden. En zo snel! Dat extrapoleert in technische mogelijkheden.” Ook Holweg is gefascineerd door AI: “Mijn achtergrond is sociale wetenschappen, op het snijvlak mens en technologie. Mijn interesse ligt niet zozeer in wat AI is, maar in wat AI doet. Waar het raakt aan mens en maatschappij. Meedenken over de Proof of Concept (PoC) is nuttig voor mij als beleidsadviseur en voor de ethiek. Wat willen we met eventuele vervolginstrumenten en de governance straks?”
Draagvlak
"Met deze veelbelovende resultaten is het zonde om er geen vervolg aan te geven!"
Eerste stap om het experiment op te starten was bestuurlijk draagvlak. Een schone taak voor Holweg, die niet alleen meedacht over de inhoud, maar ook de interne communicatie op zich nam. “AI is best spannend. Maar als provincie hebben we de ambitie om te innoveren. Met dit experiment konden we het innovatieproces nieuw leven inblazen.”
Het is belangrijk om te experimenteren met en te leren van AI. “Traditionele software is voorspelbaar: als je de regels goed volgt, krijg je altijd dezelfde uitkomst. Met AI tast je meer in het duister. Je wordt verrast met briljante oplossingen, maar ook met misleidende antwoorden. Juist daarom goed om te verkennen wat er kan. Dat was het Tactisch Overleg van managementteam I&A met ons eens.”
Dus ging de werkgroep aan de slag.
Het experiment

Het experiment gebruikt de nieuwste generatieve AI om bestanden sneller en efficiënter te voorzien van metadata. Een proces dat normaliter bijzonder tijdrovend is. In het experiment zijn Cuppen en de zijnen aan de slag gegaan met 20-40 documenten zonder privacyrisico’s. “We wilden kijken of we in staat waren om met 97% nauwkeurigheid te metadateren”.
Cuppen en zijn werkgroep hebben niet zelf een LLM gebouwd, maar een bestaand model, GPT4, getraind: op het platform van een grote cloudleverancier. “Dat voor elkaar krijgen, had wat voeten in de aarde. Wij hebben een ontwikkelaccount aangevraagd bij onze bestaande cloudleverancier. Met de garantie dat de data binnen de EU worden verwerkt. En dat data niet worden gebruikt om AI te trainen. Daar hebben we heel erg op gelet. Zo hebben we gewerkt en konden we de privacy waarborgen binnen het experiment.”
Tot slot volgde een arbeidsintensieve steekproef, een handmatige check, op de eerste gemetadateerde documenten. De eerste impressies van GPT4 waren veelbelovend. “Een stuk beter dan zijn voorganger,“ meent Holweg. “Maar het model heeft scherpe instructies nodig. GPT4 haalde veel juiste metadata op, maar had ook een keerzijde: meer onjuiste interpretaties door dichterlijke vrijheid/aannames. Voor een vervolgexperiment moeten we meer goede voorbeelden aan het model voeden, of een instructie per bestandssoort schrijven. Dus een andere instructie voor bijvoorbeeld e-mails dan voor documenten en pdf’s. We hebben veel ideeën voor een vervolgfase. Dat gaan we terugkoppelen: met deze veelbelovende resultaten is het zonde om er geen vervolg aan te geven!”
"Ik ben er trots op dat we ons AI- experiment met alleen provincieresources en zonder externe hulp hebben gedaan."
AI trainen

Die ‘training’ is een kwestie van een superslimme werkinstructie schrijven: “Hoe moet LLM de xml voor metadata vullen. Onze datascientist-collega heeft allemaal scripts geschreven in Python om de boel aan elkaar te knopen en om output te krijgen.”
Voor de datascientist in het team was duidelijk dat prompting, AI instrueren, een vaardigheid op zich is. Het team is van plan om bredere AI-awareness te creëren binnen de organisatie en medewerkers te trainen in het effectief gebruiken van AI.
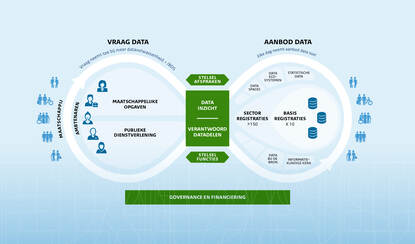
Of het goed genoeg is voor productie, wil Cuppen in de volgende fase uitzoeken: “Er is een doorstart nodig om de 60.000 bestanden te koppelen. De infrastructuur is er, maar je moet ervoor waken dat e.e.a. niet op een schijf van een datateam terechtkomt, waardoor iedereen erbij zou kunnen. Dat heeft niks met AI te maken. Je moet je experiment goed/zorgvuldig ‘sandboxen‘: oefenen in een veilige, afgesloten testomgeving waar je kunt kunnen experimenteren met AI zonder risico's voor de productiesystemen. Voordat je de 60.000 bestanden gaat metadateren zoals in het experiment, zul je een Data Protection Impact Assessment (DPIA) moeten doen.”
Resultaten en geleerde lessen
Het experiment leverde veelbelovende resultaten op, hoewel de nauwkeurigheid van 97% niet werd gehaald. Holweg: “We hadden de lat hoog gelegd, maar AI wordt strenger beoordeeld dan mensen. We accepteren van mensen dat ze fouten maken, maar van AI niet,” schetst Holweg. Toch vindt ze de resultaten waardevol: “Door het experiment leren we over de toepassingsmogelijkheden van AI. Ook omdat we de business betrekken. Daar is veel te winnen. AI houdt je een spiegel voor: je leert heel veel over hoe je je werkt uitvoert. Je moet de werkprocessen op je afdeling scherp maken om ze te vertalen naar een heldere instructie voor een LLM!”
Je móet veel testen, denkt Cuppen. “Om de prompting goed te krijgen, de instructies te finetunen en om de resultaten te controleren.” Bovendien zijn er tijdens het experiment nieuwere LLM’s uitgekomen. “Misschien doen die het al weer beter.”
AI kan briljante oplossingen bieden, denkt Holweg, "maar kan ook verrassende en soms misleidende antwoorden geven. Daarom moet je te allen tijde scherp blijven op de instructies die je aan het model geeft."
Investering beperkt
Cuppen tipt dat je voor een dergelijk experiment ervaring met cloudservices en de goede infrastructuur moet hebben. “Dat vereist dat je governance goed geregeld is. Verder is het niet zo spannend.” Sterker nog: “Uiteindelijk hebben we er maar 10 euro aan uitgegeven. Ook omdat we met kleine datasets hebben gewerkt, heeft het ons feitelijk niks gekost. Het was wel een fikse tijdsinvestering.”
Al met al heeft Cuppen er veel vertrouwen in dat Gelderland een behoorlijk goed werkend model krijgt: “Ik ben er trots op dat we ons AI- experiment met alleen provincieresources en zonder externe hulp hebben gedaan. Door alles zelf te doen en begrijpen we hoe het werkt. En kunnen we later ook beter externe partijen aansturen.”
Interprovinciale samenwerking
Het experiment heeft geleid tot verdere samenwerking tussen provincies. Maar het is goed om klein te beginnen, dan krijg je sneller dingen voor elkaar, is Cuppens ervaring.
Holweg vertelt dat de werkgroep het experiment heeft gepresenteerd op de AI-dag in Zwolle. “Andere provincies hebben dezelfde vraagstukken. Samen kunnen we tot goede oplossingen komen. Zo experimenteert Zeeland ook met AI. Niet met machine learning, maar met meer klassieke code. Dat wisten we niet van elkaar. Nu hebben we een tweeledig leerproces en kunnen we op termijn onze resultaten uitwisselen.”
Inmiddels is er een interprovinciale werkgroep. Cuppen: “Als we besluiten tot een doorstart, gaan we dat met die groep doen. Als dat succesvol is, kunnen we weer verbreden. Maar als overheid hechten we aan de overheidsbrede open source-gedachte. En hoe groter het wordt, hoe lastiger het is om het platform geschikt te maken voor alle organisaties. Dan moet je misschien op zoek gaan naar een generieker platform. En de stap maken naar een meer interprovinciale techniek.”
Door het gesprek te voeren, wordt het idee meer gedragen, denkt Holweg. “En vinden we meer gedeeld eigenaarschap over het experiment vanwege een grote gedeelde uitdaging: informatiehuishouding. AI biedt mogelijkheden om informatiebeheer te optimaliseren en met de juiste inzet kunnen we veel bereiken.”
Cuppen denkt dat het geen rocket science is wat zijn provincie aan het doen is: “Je moet het vooral zien als oefenen. Als overheid doen we ervaring op, voordat we worden ingehaald door de markt. Commerciële bedrijfjes rondom archivering doen hetzelfde als wij. Vermoedelijk worden zij er uiteindelijk beter in. Maar wij kunnen ons richten op complexe provinciale opgaven waarmee we specifieke problemen van inwoners kunnen oplossen.”
“AI is geen wondermiddel; het is technologie, een instrument. Of het goed werkt, ligt aan hoe wij het inzetten."
Van Proof of Concept naar Proof of Value
Het team is vastbesloten om door te gaan met de opgedane kennis. Holweg: “In de POC-fase kijken we of het idee levensvatbaar is: kunnen we dit bouwen? Om te beoordelen of we ook kunnen opschalen, willen we gaan pilotten met inhoudelijk betrokkenen van DIV. Dan komen bij de Proof of Value: voegt metadateren met AI daadwerkelijk waarde toe? Word je echt ontzorgd in het werkproces? Kunnen we hard work uitbesteden aan AI, waardoor er voor de medewerkers ruimte komt voor good work?”
Cuppen: “Als we richting productie gaan, moeten we goed nadenken over ethische eisen en control eisen. We moeten erop kunnen vertrouwen dat het aantoonbaar goed werkt. Dán kan de oplossing beschikbaar worden voor alle provincies.”
Meer AI-experimenten?
Het AI-experiment met metadateren, gaat als een lopend vuurtje. Ook andere afdelingen dan DIV weten de werkgroep van Cuppen en Holweg te vinden. Inmiddels ligt er een portfolio met andere interessante businesscases. En, vertelt Holweg: “Samen met 5 andere provincies hebben we 8 AI-trainees aangenomen. Die 8 gaan daadwerkelijk AI-oplossingen bouwen. Met als eerste doel: experimenteren en leren. Door onze ervaringen met het metadata-experiment hebben we de weg vrijgemaakt voor grotere experimenten. De trainees zijn 1 oktober gestart. Zij kunnen ook verder met metadateren. Zij kunnen een AI-oplossing ontwikkelen om de automatisch gegenereerde metadata te valideren. Handmatige controle is tijdrovend. Dus een slimmere oplossing is waardevol. Dus op termijn kunnen we vertellen wat zij hebben geleerd.”
Na de experimenteerfase
Als je (delen van) AI voor besluitvorming inzet, moet ook dát stuk besluitvorming inzichtelijk zijn, legt Holweg uit: “We willen inzage in zo’n LLM: wat gebeurt er daarbinnen? We willen een open en transparante overheid zijn. Het proces dat AI uitvoert, moet je eigenlijk een soort beslisboom kunnen vullen. Want wat er uitrolt, is een interpretatie. En je gaat er maatregelen op baseren. Je raakt er inwoners en bedrijven mee. Dus het moet goed uitlegbaar en controleerbaar zijn.”
AI is een instrument
“AI is geen wondermiddel,” ziet Holweg. “Het is nog steeds technologie, een instrument. Of het goed werkt, ligt aan hoe wij het inzetten. We moeten blijven nadenken, het ethische gesprek voeren, en het juiste doen.”